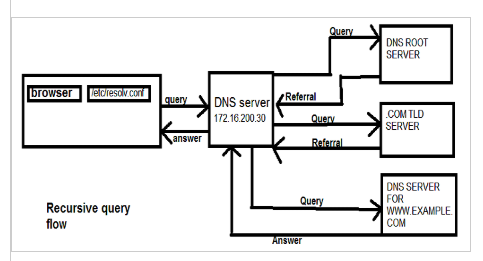
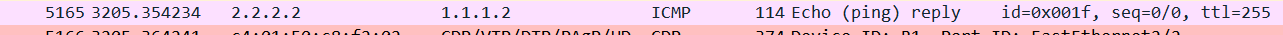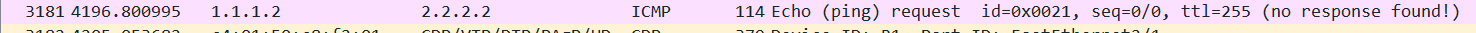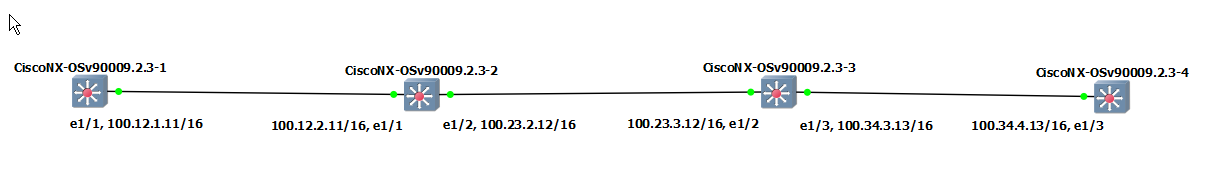Recently, I have some questions about the ECMP load-balancing on CISCO switch. I have already known that the traffic will be distrubute according to each interfaces. However, I can not understand the method for this. This is good chance for me to learn.
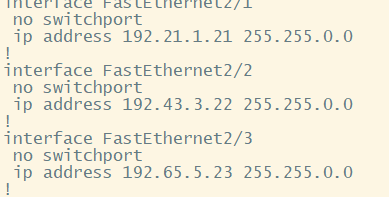
By this instruction, I can see the configuration paramter on interface like below.
For this verification, I will set up the GNS simulator like below. There are 3 links connected each other.
I will see the wireshark packet over each interface.
1. Per-Destination Algorithm
"Per-Desination" is default configuration. Therefore, it is now shown when I enter the CLI "ip load-sharing per-destination".
This algorithm is more similar with hashing method. The traffic will transfer over same interface. R1 has 3 loopback IP address, 1.1.1.1, 1.1.1.2 and 1.1.1.3. I will do ICMP with source. The traffic will use different links. However, It will be the same link when the source and destination are same.
[R1# ping 2.2.2.2 source 1.1.1.1 repeat 1]
R1 send ICMP request over Fa 2/1 and received over Fa 2/3.
[R1# ping 2.2.2.2 source 1.1.1.2 repeat 1]
R1 send ICMP request over Fa 2/2 and received over Fa 2/1.
[R1# ping 2.2.2.2 source 1.1.1.3 repeat 1]
R1 send ICMP request over Fa 2/2 and received over Fa 2/1.
Now I will do again in 10 minutes. It will be the same result.
[R1# ping 2.2.2.2 source 1.1.1.2 repeat 1]
R1 send ICMP request over Fa 2/2 and received over Fa 2/1.
2. Select load-sharing algorithm for "Per-Destination"
This configuration give some option between R1 and R2. "Per-Destination" is the hashing algorithm. Thus R1 and R2 will show the same result. Because of this, some link can be intensive. For example, R1 --> Link 1 --> R2, R2 --> Link 1 --> R1 can be happend. Thus "Universal algorithm" make more dynmic distrubution on each switch with difference link.
3. Per Packet Algorithm.
I will configure like below on R1 and R2 switch.
After then, I will try to ping to R2. R2 has loopback IP address, 2.2.2.2/32.
I will get the result like below. This result show that the traffic are distributed by packet, even if it is single connection (source-destination IP address pair)
This is the sample case. "var 1 = 10;" is the part to define the variable. It is different from others. There is no type such as int, float or string. In the Golang, the fomular is like below.
var <names> <type> = <expression>
Value names can be multiple. With this statements, the same case should be written like below.
package main
import "fmt"
func main(){
var i int = 10;
fmt.Printf("%d\n",i);
}
In the GoLang, there is implicit statments like below. The "type" is followed from expression type.
<names> := <expression>
Because of this, the sample case will be re-written like below
Today, I will start to learn how to use the GoLang. I am not good at the programming languarge. With this chance, I I hope that I can read the GoLang with basic grammer.
In this post, I wrote how to configure DNS servers (Bind9). In this post, I will setup the DNSSEC to enforce DNS secrutiy from the attacker. In fact, I am not friendly with DNS element. So I will follow this instruction.
At first, I need to update master DNS server configuration to enable DNSSEC function. Open "/etc/bind/named.conf.option" and update like below (red text)
# cat /etc/bind/named.conf.options
options {
directory "/var/cache/bind";
recursion no;
listen-on port 53 { 10.10.0.124; };
allow-transfer { none; };
dnssec-enable yes;
dnssec-validation yes;
dnssec-lookaside auto;
auth-nxdomain no; # conform to RFC1035
listen-on-v6 { any; };
};
DNSSEC required the ZSK KEY (Zone Signing Key) and KSK KEY (Key Signing Key). Both key are called as DNSKEY. I have to generated these. To generate encryption key, I need entropy algorithm. "havedged" is good solution for this.
# apt-get install haveged
Now, I can generate. Please note that Key files should be located on the same directory of zone files.
# cd /var/cache/bind/zones
After run command to geneate, I can see the 2 files like below. These file are Zone Signing Key.
# dnssec-keygen -a NSEC3RSASHA1 -b 2048 -n ZONE db.g.crenet.com
All of these step are for creating signed zone file. Therefore, I will update zone file from now. Open zone file what I make secure and Include the key files above.
Now, I am ready to sign the zone file. I will run "dnssec-signzone -3 <salt> -A -N INCREMENT -o <zonename> -t <zonefilename>". "<Salt>" value is the random number. I can generate like below
listen-on port 53 { 10.10.0.204; }; # ns1 private IP address - listen on private network only
allow-transfer { none; }; # disable zone transfers by default
dnssec-enable yes;
dnssec-validation yes;
dnssec-lookaside auto;
dump-file "/var/cache/bind/dumps/named_dump.db";
auth-nxdomain no; # conform to RFC1035
listen-on-v6 { any; };
};
5. Configure DS records with the registrar.
When I create Signed zone file, "dsset-g.crenet.com" file is also generated which include "DS" record.
# cat dsset-g.crenet.com.
g.crenet.com. IN DS 33324 7 1 CFE9B08DB55C9EF23AAE19979FB2A48467C1061E
g.crenet.com. IN DS 33324 7 2 1245F5EB80E7A2F6CE9A64A9C69A94EFBC800D60EA4065B96B7FF501 AB6816D2
To publish this DNS server with DNSSEC, I have to offer these DS record to my DNS registrar. (DNS registrar mean the represtative compay which has the role to register DNS, such as GoDaddy or Gabia.
How to configure DNS bind9 configuration in Ubuntu
Recently, I need to learn about DNS system. In fact, I have not considered about this system so far. To understand about this as the begineer. I will memorize how to configure simply.
1. Pre-requisite.
I have four servers with Ubuntu 16.04 in AWS. Each server has the Public IP address.
2. Installation of bind9 packages
In fact, I do not know anything at this time. I need some instructions. I will follow this instruction basically. At first I need to update hosts name.
# hostname ns1
# hostname ns2
# hostname ns3
And I will update repository and install the bind packages like below. I will repeate this step in each servers, ns2 and ns3 also.
# apt-get update
# sudo apt-get install bind9 bind9utils bind9-doc
Installation is completed. I can see the directory and files under /etc/binddirectory.
At first, I will edit "named.conf.options". In this file, I will add some options to work well as the DNS server. This configuration is not applied to only primary. I will edit all of servers.
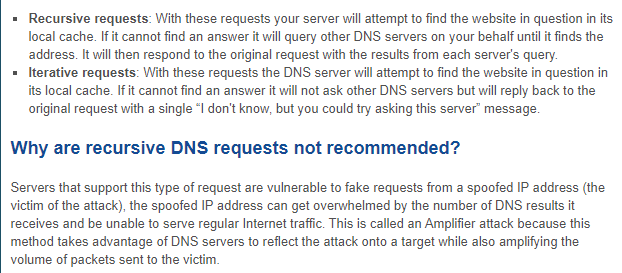
In above, there is "acl" field. It is the represatative name for allow-recursion. "recursion yes" means enable the recurive query from other DNS servers which is defined in "allow-recursion". In this instrucion, It shows what the recursive query is.
In this instruction, it is more simple contexts comparing with "iterative request".
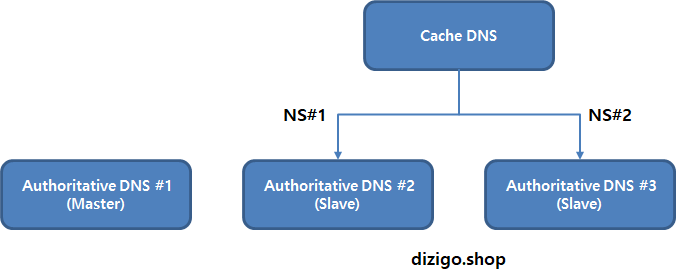
If I do not want to use this recursion, I can change to "recursion no;" In my case, my authoritative DNS servers will be end of step for Domain. So I will disable the recursion. "allow-transfer { 10.10.0.99; 10.10.0.39; };" means transfering zone file to listed DNS servers which are refered as slave servers.
auth-nxdomain no; # conform to RFC1035 listen-on-v6 { any; }; };
# Slave DNS (AuthoritativeDNS) servers
options { directory "/var/cache/bind";
recursion no; listen-on port 53 { 10.10.0.72; };
dnssec-validation auto;
auth-nxdomain no; # conform to RFC1035 listen-on-v6 { any; }; };
After these configurations, I can check the configuration is correct or not.
# service bind9 restart
# # named-checkconf named.conf.options
If I do not get any answer or failed message, It works correct. In above, I defined "allow-transfer" like "allow-transfer { 10.10.0.99; 10.10.0.39; };". This parameter is the global value. Therefore, it is applied for all of zone files. It need to be limited sometimes. In the instruction, allow-transfer { none; }; is recommended.
auth-nxdomain no; # conform to RFC1035 listen-on-v6 { any; }; };
# Slave DNS (AuthoritativeDNS) servers
options { directory "/var/cache/bind";
recursion no; listen-on port 53 { 10.10.0.72; };
dnssec-validation auto;
auth-nxdomain no; # conform to RFC1035 listen-on-v6 { any; }; };
I will define "allow-transfer" in "named.conf.local" individually in every zone difinition. I will edit the "named.conf.local". It looks like below.
# Master DNS (AuthoritativeDNS) server
zone "dizigo.shop" { type master; file "/etc/bind/zones/db.dizigo.shop"; allow-transfer { 10.10.0.99; 10.10.0.39; }; }; zone "10.10.in-addr.arpa" { type master; file "/etc/bind/zones/db.10.10"; allow-transfer { 10.10.0.99; 10.10.0.39; }; };
# Slave DNS (Authoritative DNS) servers
zone "dizigo.shop" { type slave; file "db.dizigo.shop"; masters { 10.10.0.72; }; }; zone "10.10.in-addr.arpa" { type slave; file "db.10.10"; masters { 10.10.0.72; }; };
In above, I defined "forward zone" and "reverse zone". (Please this does not mean zone file) I suppose the one of 10.10.0.0/16 ip addresses will be mapped with Domain. In this file, It show how many zone file are existed and the each properties. I wrote 2 types of configuration for master and slave. In this "master", I can define "allow-transfer { 10.10.0.99; 10.10.0.39; };" in each zone definition. (Even if I will explain later in this post) In "slave", I can define "masters" as the source.
I will locate the zone file under "/etc/bind/zones". If you do not have zone directory, I need to create before.
# mkdir -r /etc/bind/zones
After these configurations, I can check the configuration is correct or not.
# service bind9 restart
# named-checkconf named.conf.local
# named-checkconf
3. Createing the Forward and reverse zone files.
Under the "/etc/bind" directory, there is the sample file for these.
# Forward zone file sample
root@ns1:/etc/bind# cat /etc/bind/db.local $TTL 604800 @ IN SOA localhost. root.localhost. ( 2 ; Serial 604800 ; Refresh 86400 ; Retry 2419200 ; Expire 604800 ) ; Negative Cache TTL ; @ IN NS localhost. @ IN A 127.0.0.1 @ IN AAAA ::1
# Reverse zone file sample
root@ns1:/etc/bind# cat /etc/bind/db.127 $TTL 604800 @ IN SOA localhost. root.localhost. ( 1 ; Serial 604800 ; Refresh 86400 ; Retry 2419200 ; Expire 604800 ) ; Negative Cache TTL ; @ IN NS localhost. 1.0.0 IN PTR localhost.
I will copy and edit this files for my zone file. This step is depends on your environments. It will be different from me
# cp db.local /etc/bind/zones/db.dizigo.shop
# cp db.127 /etc/bind/zones/db.10.10
Open the forward zone file and edit at first. It looks like below.
$TTL 60
@ IN SOA ns1.dizigo.shop admin.dizigo.shop. (
3 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
; name servers - NS records
IN NS ns1.dizigo.shop.
IN NS ns2.dizigo.shop.
IN NS ns3.dizigo.shop.
; name servers - A records
ns1.dizigo.shop. IN A 10.10.0.72
ns2.dizigo.shop. IN A 10.10.0.99
ns3.dizigo.shop. IN A 10.10.0.39
; sample - A records
www.dizigo.shop. IN A 10.128.100.101
ftp.dizigo.shop. IN A 10.128.200.101
I edit the TTL time for caching. If there is the caching DNS server in front of these authoritative DNS servers, the Caching server does not ask again during this time. I will adjust for 60 seconds. Serail number is increased. Every time, I edit zone file, I have to increase this number. This number is used for the slave servers to determince download zone file or not. I added all of name servers in end of SOA field. For reverse zone file, it is similar with forward zone file. It looks like below.
$TTL 60 @ IN SOA ns1.dizigo.shop. admin.dizigo.shop. ( 2 ; Serial 604800 ; Refresh 86400 ; Retry 2419200 ; Expire 604800 ) ; Negative Cache TTL
; name servers - NS records IN NS ns1.dizigo.shop. IN NS ns2.dizigo.shop. IN NS ns3.dizigo.shop.
; PTR Records 72.0 IN PTR ns1.dizigo.shop. 99.0 IN PTR ns2.dizigo.shop. 39.0 IN PTR ns3.dizigo.shop.
Most of values are same. Add all of name servers end of SOA field, then add PTR records. After all of these, I can check my configuration.
6. Create Caching DNS server without zone file (Only Forwarding caching DNS server)
Now, I create the Caching DNS server in front of Authoritative DNS servers. I will refere this instruction. Most of steps are similar with above. I have already written above.
In the instrucion, there is another term, "allow-query". This is same with "allow-recursion". So In my case I will use again in this post. I need to define "forwarders" which point to DNS server whiech handdle the recursive query. In my case, the authoritative DNS servers are listed in here.
At this time, I want to make this Caching server to work as forwarder (This server does not response against the query reqeust itself). So I will add "forward only;" option. Final thing I need to edit is dnssec. In fact, I do not know what this is exactly. Anyway, this part make the server and client more secure. So, the my configuration of "named.conf.opiton" look like below.
listen-on port 53 { 10.10.0.37; }; # ns1 private IP address - listen on private network only
allow-transfer { none; }; # disable zone transfers by default
forwarders {
10.10.0.99;
10.10.0.72;
};
forward only;
dnssec-enable yes;
dnssec-validation yes;
auth-nxdomain no; # conform to RFC1035
listen-on-v6 { any; };
};
After this configuration, I need to check the configuration with "named-checkconf" and restart bind
# named-checkconf
# service bind9 restart
7. Verfication of Caching server (Clean cached DB)
In this blog, there is the way to view cahce status.
# Run Command
# rndc dumpdb -cache
# Log messages (Error)
Sep 13 14:38:25 cache kernel: [195574.027929] audit: type=1400 audit(1568385505.800:83): apparmor="DENIED" operation="mknod" profile="/usr/sbin/named" name="/named_dump.db" pid=25682 comm="named" requested_mask="c" denied_mask="c" fsuid=112 ouid=112 Sep 13 14:38:25 cache named[25678]: received control channel command 'dumpdb -cache' Sep 13 14:38:25 cache named[25678]: could not open dump file 'named_dump.db': permission denied
This error happend due to permission of file location which is created by the command. Therefore, I need to re-define the path for the dump file in the configuration. Please read this instruction.
listen-on port 53 { 10.10.0.37; }; # ns1 private IP address - listen on private network only
allow-transfer { none; }; # disable zone transfers by default
forwarders {
10.10.0.99;
10.10.0.72;
};
forward only;
dnssec-enable yes;
dnssec-validation yes;
dump-file "/var/cache/bind/dumps/named_dump.db";
auth-nxdomain no; # conform to RFC1035
listen-on-v6 { any; };
};
"dump-file "/var/cache/bind/dumps/named_dump.db";" is added int the configuration. After then, check configuration and restart. (Please note that the file should be located under /var/cache/bind directory)
# Run Command
# rndc dumpdb -cache
# /var/cache/bind/dumps# ls named_dump.db
I can see the file created. I can also read this file. The result look like below
If I want to clean this db and caching. I can run like below. Flush and service restarted are necessary.
# rndc flush
# service bind9 restart
8. Create Caching DNS server with zone file (Delegating sub-domain)
Please note that I can not delegate other domain. I can only delegate sub-domain. For example, "some-name.origin-domain.com --> some-domain.com" is not possible. "some-name.origin-domain.com --> some-name.sub-domain.origin-domain.com" is only possible
Because of above, I use another name "ozigo.shop". (So far, I used "dizigo.shop")
I will follow this instruction. Caching DNS server can have zone file and handle the query directly. For this, I will do some of changes. First I will remove "forward only;" and "forwarders". Therefore "named.conf.option" is look like below
listen-on port 53 { 10.10.0.37; }; # ns1 private IP address - listen on private network only
allow-transfer { none; }; # disable zone transfers by default
dnssec-enable yes;
dnssec-validation yes;
dump-file "/var/cache/bind/dumps/named_dump.db";
auth-nxdomain no; # conform to RFC1035
listen-on-v6 { any; };
};
And then, I need other configuration file and zone file, "named.conf.local" and "zone file included sub-domain"
# cat named.conf.local
zone "ozigo.shop" {
type master;
file "/etc/bind/zones/db.ozigo.shop";
};
I used "$ORIGIN" term to seperate zone between ozigo.shop and ns.ozigo.shop. The red text show how to delegate sub-domain reqursion. The request query for "ns.ozigo.shop" will be sent to "ns1.ns.ozigo.shop" which has 10.10.0.72 IP address. The authoritative DNS which has zone file will be like below.
root@cache:/var/cache/bind/zones# cat db.crenet.com $ORIGIN crenet.com. $TTL 10 @ IN SOA crenet.com. admin.crenet.com. ( 3 ; Serial 604800 ; Refresh 86400 ; Retry 2419200 ; Expire 604800 ) ; Negative Cache TTL ; IN NS ns1.crenet.com. ns1.crenet.com. IN A 10.10.0.204
; www.crenet.com. IN CNAME www.g.crenet.com.
$ORIGIN g.crenet.com. @ IN NS ns1.g.crenet.com. IN NS ns2.g.crenet.com. ns1.g.crenet.com. IN A 10.10.0.124 ns2.g.crenet.com. IN A 10.10.0.225
# cat zones/db.ns.ozigo.shop
$TTL 60
@ IN SOA ns1.ns.ozigo.shop. admin.ns.ozigo.shop. (
3 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
; name servers - NS records
IN NS ns1.ns.ozigo.shop.
; name servers - A records
ns1.ns.ozigo.shop. IN A 10.10.0.72
; sample - A records
recursion.ns.ozigo.shop. IN A 200.200.200.200
My final goal is looking up "recursion.ozigo.shop". When I try to dig from remote client, the result should be like below.
In this post, I will handle the OSPF cost (OSPF cost and auto-cost reference-bandwidth). Normally, I use the OSPF with default setting.
1. Pre-requisite.
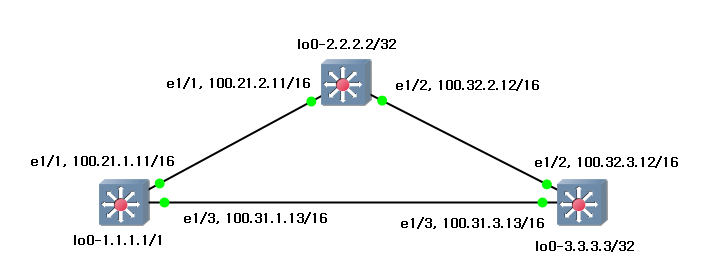
This is my environment to re-produce. I will write the simple configuration with default values.
s1 (1.1.1.1/32)
s2 (2.2.2.2/32)
s3 (3.3.3.3/32)
feature ospf
interface Ethernet1/1
no switchport
ip address 100.21.1.11/16
ip router ospf 1 area 0.0.0.0
no shutdown
interface Ethernet1/3
no switchport
ip address 100.31.1.13/16
ip router ospf 1 area 0.0.0.0
no shutdown
interface loopback0
ip address 1.1.1.1/32
ip router ospf 1 area 0.0.0.0
router ospf 1
router-id 1.1.1.1
feature ospf
interface Ethernet1/1
no switchport
ip address 100.21.2.11/16
ip router ospf 2 area 0.0.0.0
no shutdown
interface Ethernet1/2
no switchport
ip address 100.32.2.12/16
ip router ospf 2 area 0.0.0.0
no shutdown
interface loopback0
ip address 2.2.2.2/32
ip router ospf 2 area 0.0.0.0
router ospf 2
router-id 2.2.2.2
feature ospf
interface Ethernet1/2
no switchport
ip address 100.32.3.12/16
ip router ospf 3 area 0.0.0.0
no shutdown
interface Ethernet1/3
no switchport
ip address 100.31.3.13/16
ip router ospf 3 area 0.0.0.0
no shutdown
interface loopback0
ip address 3.3.3.3/32
ip router ospf 3 area 0.0.0.0
router ospf 3
router-id 3.3.3.3
2. Verify default status.
With default values, I can see the routing table over s1.
s1# show ip route
1.1.1.1/32, ubest/mbest: 2/0, attached
*via 1.1.1.1, Lo0, [0/0], 00:39:21, local
*via 1.1.1.1, Lo0, [0/0], 00:39:21, direct
2.2.2.2/32, ubest/mbest: 1/0
*via 100.21.2.11, Eth1/1, [110/41], 00:35:38, ospf-1, intra
3.3.3.3/32, ubest/mbest: 1/0
*via 100.31.3.13, Eth1/3, [110/41],00:33:43, ospf-1, intra
100.21.0.0/16, ubest/mbest: 1/0, attached
*via 100.21.1.11, Eth1/1, [0/0], 00:36:44, direct
100.21.1.11/32, ubest/mbest: 1/0, attached
*via 100.21.1.11, Eth1/1, [0/0], 00:36:44, local
100.31.0.0/16, ubest/mbest: 1/0, attached
*via 100.31.1.13, Eth1/3, [0/0], 00:34:24, direct
100.31.1.13/32, ubest/mbest: 1/0, attached
*via 100.31.1.13, Eth1/3, [0/0], 00:34:24, local
100.32.0.0/16, ubest/mbest: 2/0
*via 100.21.2.11, Eth1/1, [110/80], 00:33:43, ospf-1, intra
*via 100.31.3.13, Eth1/3, [110/80], 00:33:43, ospf-1, intra
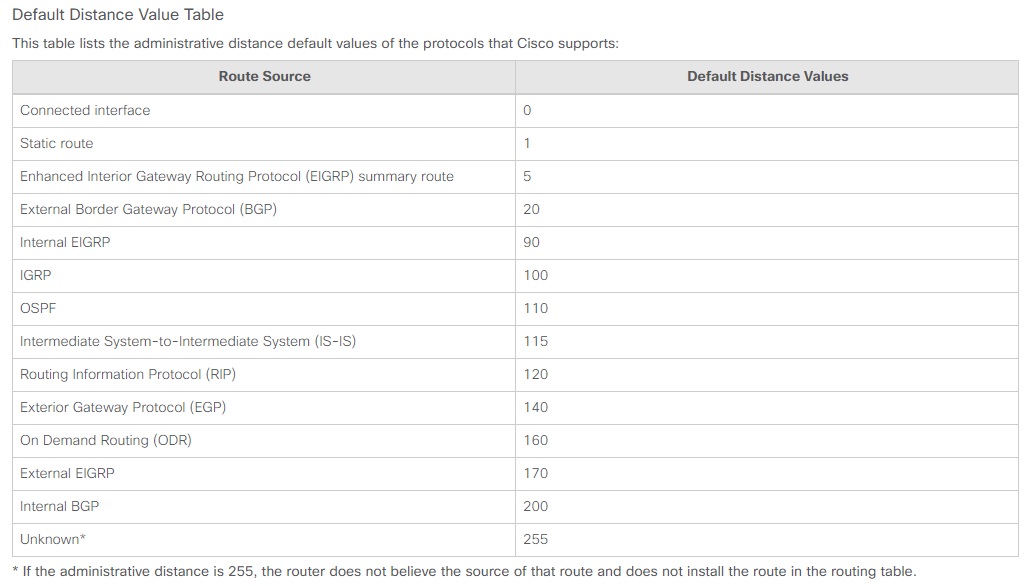
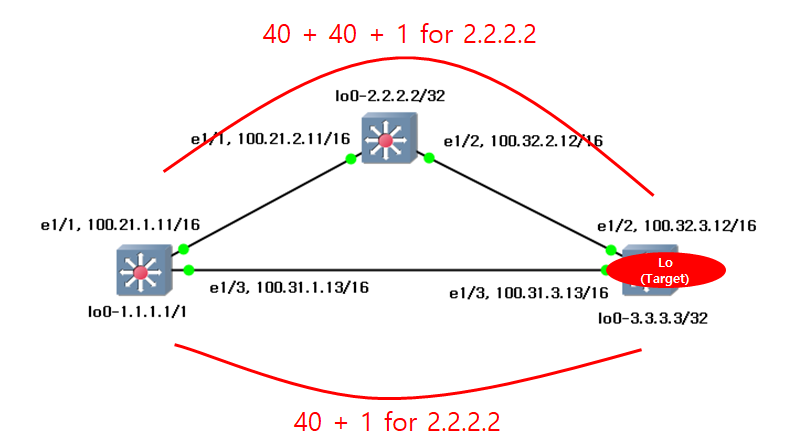
I can see the 2 kinds of values, [110/41] and [110/80]. The first value is the preference which is called as the administrative distance. In this instruction, there is the table list. In my case, I used the OSPF protocol which has 110 value as the default distance values.
From [110/41] and [110/80], "41" and "80" are the metric cost. Before calcuate these values, I need to understand the "auto-cost referece-bandwidth".
3. About auto-cost referece-bandwidth.
The cost is obtained by "auto-cost reference-bandwidth / interface bandwidth". In this instruction, it show how to configure this auto-cost reference-bandwidth. This is overview.
In my case, I used the Cisco Nexus image. Therefore, the default value is like below from this instruction.
I can verify this value with command, "show ip ospf". This is the sample from s1.
s1# show ip ospf
Routing Process 1 with ID 1.1.1.1 VRF default
Routing Process Instance Number 1
Stateful High Availability enabled
Graceful-restart is configured
Grace period: 60 state: Inactive
Last graceful restart exit status: None
Supports only single TOS(TOS0) routes
Supports opaque LSA
Administrative distance 110
Reference Bandwidth is 40000 Mbps
SPF throttling delay time of 200.000 msecs,
SPF throttling hold time of 1000.000 msecs,
SPF throttling maximum wait time of 5000.000 msecs
LSA throttling start time of 0.000 msecs,
LSA throttling hold interval of 5000.000 msecs,
LSA throttling maximum wait time of 5000.000 msecs
Minimum LSA arrival 1000.000 msec
LSA group pacing timer 10 secs
Maximum paths to destination 8
Number of external LSAs 0, checksum sum 0
Number of opaque AS LSAs 0, checksum sum 0
Number of areas is 1, 1 normal, 0 stub, 0 nssa
Number of active areas is 1, 1 normal, 0 stub, 0 nssa
Install discard route for summarized external routes.
Install discard route for summarized internal routes.
Area BACKBONE(0.0.0.0)
Area has existed for 02:52:56
Interfaces in this area: 3 Active interfaces: 3
Passive interfaces: 0 Loopback interfaces: 1
No authentication available
SPF calculation has run 9 times
Last SPF ran for 0.001811s
Area ranges are
Number of LSAs: 6, checksum sum 0x30590
Reference Bandwidth is 40000 Mbps. In s1, ethernet 1/1 and ethernet 1/3 have 1Gbps Bandwidth
s1# show inter et 1/1 Ethernet1/1 is up admin state is up, Dedicated Interface Hardware: 100/1000/10000 Ethernet, address: 0cfc.6a48.f207 (bia 0cfc.6a48.f208 ) Internet Address is 100.21.1.11/16 MTU 1500 bytes, BW 1000000 Kbit, DLY 10 usec reliability 255/255, txload 1/255, rxload 1/255 Encapsulation ARPA, medium is broadcast full-duplex, 1000 Mb/s
s1# show inter et 1/3 Ethernet1/3 is up admin state is up, Dedicated Interface Hardware: 100/1000/10000 Ethernet, address: 0cfc.6a48.f207 (bia 0cfc.6a48.f20a ) Internet Address is 100.31.1.13/16 MTU 1500 bytes, BW 1000000 Kbit, DLY 10 usec reliability 255/255, txload 1/255, rxload 1/255 Encapsulation ARPA, medium is broadcast full-duplex, 1000 Mb/s
Thus, 40000 Mbps / 1000 Mbps = 40. This is the cost. I can verify the value only with command "show ip ospf interface" also. The below is the sample from s1.
Timer intervals: Hello 10, Dead 40, Wait 40, Retransmit 5
Hello timer due in 00:00:03
No authentication
Number of opaque link LSAs: 0, checksum sum 0
loopback0 is up, line protocol is up
IP address 1.1.1.1/32
Process ID 1 VRF default, area 0.0.0.0
Enabled by interface configuration
State LOOPBACK, Network type LOOPBACK, cost 1
Index 1
I need to calculate these values. In this instruction, it show how to calculate and select the path.
4. Analysis the OSPF routing cost.
In s1 switch, [110/41] and [110/80] are the values as the cost.
I need to see more detail. "3.3.3.3" is the loopback interface. This IP address can be obtain with 2 path. "81" and "41" are the cost values. "41" is lower values. This is selected.
5. (Option 1) Adjust the Interface Bandwidth to change the path.
There are many method to determine the path. Most simple way is the change the interface bandwidth and speed. I change the interface bandwidth like below. Please read this instruction.
s1 (1.1.1.1/32)
s3 (3.3.3.3/32)
s1(config)# inter et 1/3
s1(config-if)# bandwidth 100000
s3(config)# inter et 1/3
s3(config-if)# bandwidth 100000
After then, I can check the interface bandwidth status
s1# show ip ospf inter et 1/3 Ethernet1/3 is up, line protocol is up IP address 100.31.1.13/16 Process ID 1 VRF default, area 0.0.0.0 Enabled by interface configuration State BDR, Network type BROADCAST, cost 400 Index 3, Transmit delay 1 sec, Router Priority 1 Designated Router ID: 3.3.3.3, address: 100.31.3.13 Backup Designated Router ID: 1.1.1.1, address: 100.31.1.13 1 Neighbors, flooding to 1, adjacent with 1 Timer intervals: Hello 10, Dead 40, Wait 40, Retransmit 5 Hello timer due in 00:00:03 No authentication Number of opaque link LSAs: 0, checksum sum 0
s3# show ip ospf interface ethernet 1/3 Ethernet1/3 is up, line protocol is up IP address 100.31.3.13/16 Process ID 3 VRF default, area 0.0.0.0 Enabled by interface configuration State DR, Network type BROADCAST, cost 400 Index 3, Transmit delay 1 sec, Router Priority 1 Designated Router ID: 3.3.3.3, address: 100.31.3.13 Backup Designated Router ID: 1.1.1.1, address: 100.31.1.13 1 Neighbors, flooding to 1, adjacent with 1 Timer intervals: Hello 10, Dead 40, Wait 40, Retransmit 5 Hello timer due in 00:00:06 No authentication Number of opaque link LSAs: 0, checksum sum 0
Now, I can see the routing table changed like below.
s1# show ip route
1.1.1.1/32, ubest/mbest: 2/0, attached
*via 1.1.1.1, Lo0, [0/0], 00:07:12, local
*via 1.1.1.1, Lo0, [0/0], 00:07:12, direct
2.2.2.2/32, ubest/mbest: 1/0
*via 100.21.2.11, Eth1/1, [110/41], 00:06:11, ospf-1, intra
3.3.3.3/32, ubest/mbest: 1/0
*via 100.21.2.11, Eth1/1, [110/81], 00:05:29, ospf-1, intra
100.21.0.0/16, ubest/mbest: 1/0, attached
*via 100.21.1.11, Eth1/1, [0/0], 00:07:13, direct
100.21.1.11/32, ubest/mbest: 1/0, attached
*via 100.21.1.11, Eth1/1, [0/0], 00:07:13, local
100.31.0.0/16, ubest/mbest: 1/0, attached
*via 100.31.1.13, Eth1/3, [0/0], 00:07:12, direct
100.31.1.13/32, ubest/mbest: 1/0, attached
*via 100.31.1.13, Eth1/3, [0/0], 00:07:12, local
100.32.0.0/16, ubest/mbest: 1/0
*via 100.21.2.11, Eth1/1, [110/80], 00:05:29, ospf-1, intra
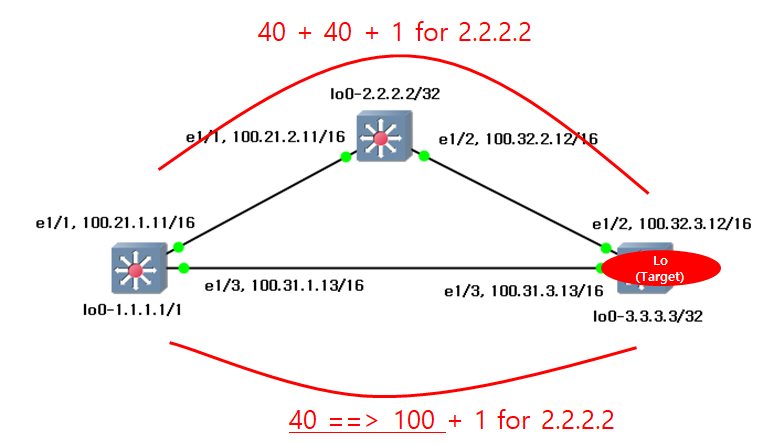
6. (Option 2) Adjust the auto-cost reference bandwidth to change the path.
Auto-cost reference-bandwidth is the global parameter. Therefore, I change this value on s1 switch. There is no effect. Also there is no effect even if I change the value on s2 switch.
In this post, I will show how this value is changed.
Therefore, the routing table will be changed like below.
s1# show ip route
1.1.1.1/32, ubest/mbest: 2/0, attached
*via 1.1.1.1, Lo0, [0/0], 00:18:15, local
*via 1.1.1.1, Lo0, [0/0], 00:18:15, direct
2.2.2.2/32, ubest/mbest: 1/0
*via 100.21.2.11, Eth1/1, [110/11], 00:02:25, ospf-1, intra
3.3.3.3/32, ubest/mbest: 1/0
*via 100.31.3.13, Eth1/3, [110/11], 00:02:25, ospf-1, intra
100.21.0.0/16, ubest/mbest: 1/0, attached
*via 100.21.1.11, Eth1/1, [0/0], 00:18:16, direct
100.21.1.11/32, ubest/mbest: 1/0, attached
*via 100.21.1.11, Eth1/1, [0/0], 00:18:16, local
100.31.0.0/16, ubest/mbest: 1/0, attached
*via 100.31.1.13, Eth1/3, [0/0], 00:18:15, direct
100.31.1.13/32, ubest/mbest: 1/0, attached
*via 100.31.1.13, Eth1/3, [0/0], 00:18:15, local
100.32.0.0/16, ubest/mbest: 2/0
*via 100.21.2.11, Eth1/1, [110/50], 00:02:25, ospf-1, intra
*via 100.31.3.13, Eth1/3, [110/50], 00:02:25, ospf-1, intra
7. (Option 3) Adjust the ip ospf cost to change the path.
This is more effective way. However, I do not recommand this way. Because this can make complexity. In this instruction, it show how to configure. This configuration will be done on each interface.
s1(config)# inter ethernet 1/3 s1(config-if)# ip ospf cost 100 s1(config-if)# exit
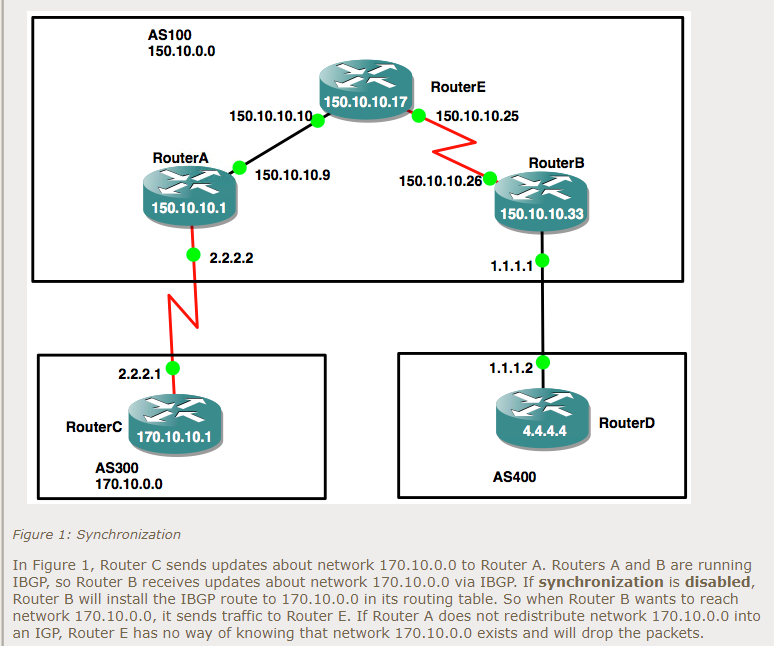
How to work BGP synchronize and next hop self with Nexus?
I have already written about BGP concept simply in this another blog in Korean. For the BGP synchronization, I have also written in this blog in Korean. For Next hop self concept, this blog will be helpful. Please do not worry even if you can not read Korean. In this post, I will reproduce this synchorization and next-hop-self with nexus switches.
1. Pre-requisite
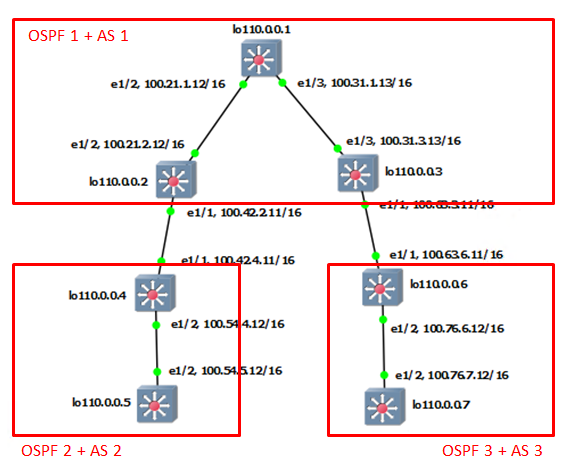
This is my environment for this post. I will configure step by step with below. For "OSPF1 + AS1" part,
s1 (lo1 110.0.0.1)
s2 (lo1 110.0.0.2)
s3 (lo1 110.0.0.3)
feature ospf
feature bgp
interface Ethernet1/2
no switchport
ip address 100.21.1.12/16
ip router ospf 1 area 0.0.0.1
no shutdown
interface Ethernet1/3
no switchport
ip address 100.31.1.13/16
ip router ospf 1 area 0.0.0.1
no shutdown
interface loopback0
ip address 110.0.0.1/32
ip router ospf 1 area 0.0.0.1
router ospf 1
router-id 110.0.0.1
feature ospf
feature bgp
interface Ethernet1/1
no switchport
ip address 100.42.2.11/16
no shutdown
interface Ethernet1/2
no switchport
ip address 100.21.2.12/16
ip router ospf 1 area 0.0.0.1
no shutdown
interface loopback0
ip address 110.0.0.2/32
ip router ospf 1 area 0.0.0.1
router ospf 1
router-id 110.0.0.2
router bgp 1
router-id 110.0.0.2
log-neighbor-changes
address-family ipv4 unicast
network 110.0.0.2/32
neighbor 100.42.4.11
remote-as 2
log-neighbor-changes
update-source loopback0
address-family ipv4 unicast
neighbor 110.0.0.3
remote-as 1
update-source loopback0
address-family ipv4 unicast
feature ospf
feature bgp
interface Ethernet1/1
no switchport
ip address 100.63.3.11/16
no shutdown
interface Ethernet1/3
no switchport
ip address 100.31.3.13/16
ip router ospf 1 area 0.0.0.1
no shutdown
interface loopback0
ip address 110.0.0.3/32
ip router ospf 1 area 0.0.0.1
router ospf 1
router-id 110.0.0.3
router bgp 1
router-id 110.0.0.3
address-family ipv4 unicast
network 110.0.0.3/32
neighbor 100.63.6.11
remote-as 3
update-source loopback0
address-family ipv4 unicast
neighbor 110.0.0.2
remote-as 1
update-source loopback0
address-family ipv4 unicast
For "OSPF2 + AS2" part,
s4 (lo1 110.0.0.4)
s5 (lo1 110.0.0.5)
feature ospf
feature bgp
interface Ethernet1/1
no switchport
ip address 100.42.4.11/16
no shutdown
interface Ethernet1/2
no switchport
ip address 100.54.4.12/16
ip router ospf 2 area 0.0.0.2
no shutdown
interface loopback0
ip address 110.0.0.4/32
router ospf 2
router-id 110.0.0.4
router bgp 2
router-id 110.0.0.4
log-neighbor-changes
address-family ipv4 unicast
network 110.0.0.4/32
neighbor 100.42.2.11
remote-as 1
log-neighbor-changes
address-family ipv4 unicast
neighbor 110.42.2.11
address-family ipv4 unicast
feature ospf
feature bgp
interface Ethernet1/2
no switchport
ip address 100.54.5.12/16
ip router ospf 2 area 0.0.0.2
no shutdown
interface loopback0
ip address 110.0.0.5/32
ip router ospf 2 area 0.0.0.2
router ospf 2
router-id 110.0.0.5
For "OSPF3 + AS3" part,
s6 (lo1 110.0.0.6)
s7 (lo1 110.0.0.7)
feature ospf
feature bgp
interface Ethernet1/1
no switchport
ip address 100.63.6.11/16
no shutdown
interface Ethernet1/2
no switchport
ip address 100.76.6.12/16
ip router ospf 3 area 0.0.0.3
no shutdown
interface loopback0
ip address 110.0.0.6/32
router ospf 3
router-id 110.0.0.6
router bgp 3
router-id 110.0.0.6
log-neighbor-changes
address-family ipv4 unicast
network 110.0.0.6/32
neighbor 100.63.3.11
remote-as 1
address-family ipv4 unicast
feature ospf
feature bgp
interface Ethernet1/2
no switchport
ip address 100.76.7.12/16
ip router ospf 3 area 0.0.0.3
no shutdown
interface loopback0
ip address 110.0.0.7/32
ip router ospf 3 area 0.0.0.3
router ospf 3
router-id 110.0.0.7
This is simple configuration. At this time, it is not perfect in traffic flow. In some case, it can not send each other. For example, S4 (110.0.0.4) and S6 (110.0.0.6) can not transfer the packets each other.
2. About BGP synchroization.
To verify the BGP synchronization, I have to look the BGP table on S3 switch.
s3# show ip bgp
BGP routing table information for VRF default, address family IPv4 Unicast
BGP table version is 16, Local Router ID is 110.0.0.3
Origin codes: i - IGP, e - EGP, ? - incomplete, | - multipath, & - backup, 2 - b
est2
Network Next Hop Metric LocPrf Weight Path
*>i110.0.0.2/32 110.0.0.2 100 0 i
*>l110.0.0.3/32 0.0.0.0 100 32768 i
i110.0.0.4/32 100.42.4.11 100 0 2 i
*>e110.0.0.6/32 100.63.6.11 0 3 i
This is so strange. Because I did not "no synchorization" in BGP configuration, "110.0.0.4" should not be displayed. In this blog, the concept of the synchronization will be explained.
I used nexus switch image for this generation. In this instruction, there are default settings. By these values, the BGP table on S3 switch displayed S4 information.
3. About Next-Hop-Self.
This is not vaild status, even if the BGP table show S4 information. It looks like normal.
s3# show ip bgp
BGP routing table information for VRF default, address family IPv4 Unicast
BGP table version is 16, Local Router ID is 110.0.0.3
Origin codes: i - IGP, e - EGP, ? - incomplete, | - multipath, & - backup, 2 - b
est2
Network Next Hop Metric LocPrf Weight Path
*>i110.0.0.2/32 110.0.0.2 100 0 i
*>l110.0.0.3/32 0.0.0.0 100 32768 i
*>i110.0.0.4/32 110.0.0.2 100 0 2 i
*>e110.0.0.6/32 100.63.6.11 0 3 i
There are 2 change. First, the status is changed as the valid. Second the next hop ip address is changed from "100.42.4.11" to "110.0.0.2". This "next-hop-self" feature make the "ebgp" existance clear. Now I will do again in s3 switch for next step.
Origin codes: i - IGP, e - EGP, ? - incomplete, | - multipath, & - backup, 2 - b
est2
Network Next Hop Metric LocPrf Weight Path
*>e110.0.0.2/32 100.63.3.11 0 1 i
*>e110.0.0.3/32 100.63.3.11 0 1 i
*>e110.0.0.4/32 100.63.3.11 0 1 2 i
*>l110.0.0.6/32 0.0.0.0 100 32768 i
By these informations, I may send traffic each other. However, I can not. Please look at the below, I send the traffic from s4 to s6.
s4# ping 110.0.0.6 source-interface loopback 0
PING 110.0.0.6 (110.0.0.6): 56 data bytes
Request 0 timed out
--- 110.0.0.6 ping statistics ---
2 packets transmitted, 0 packets received, 100.00% packet loss
I have to check the routing table s2 and s3 also. They have also information.
s2# show ip route 110.0.0.4/32, ubest/mbest: 1/0 *via 100.42.4.11, [20/0], 1d03h, bgp-1, external, tag 2 110.0.0.6/32, ubest/mbest: 1/0 *via 110.0.0.3, [200/0], 00:09:44, bgp-1, internal, tag 3
s3# show ip route 110.0.0.4/32, ubest/mbest: 1/0 *via 110.0.0.2, [200/0], 00:14:14, bgp-1, internal, tag 2 110.0.0.6/32, ubest/mbest: 1/0 *via 100.63.6.11, [20/0], 1d02h, bgp-1, external, tag 3
Now, only s1 switch has been left. In s1 switch, I did not configure for BGP. Because of this, s1 can not get any information for s4 and s6. Now I will add static route simply on s1 switch.
s1(config)# ip route 110.0.0.4/32 110.0.0.2
s1(config)# ip route 110.0.0.5/32 110.0.0.2
s1(config)# ip route 110.0.0.6/32 110.0.0.3
s1(config)# ip route 110.0.0.7/32 110.0.0.3
After this configuration add, I can send the traffic
s4# ping 110.0.0.6 source-interface loopback 0
PING 110.0.0.6 (110.0.0.6): 56 data bytes
64 bytes from 110.0.0.6: icmp_seq=0 ttl=251 time=20.858 ms
64 bytes from 110.0.0.6: icmp_seq=1 ttl=251 time=12.801 ms
64 bytes from 110.0.0.6: icmp_seq=2 ttl=251 time=25.59 ms
64 bytes from 110.0.0.6: icmp_seq=3 ttl=251 time=13.339 ms
64 bytes from 110.0.0.6: icmp_seq=4 ttl=251 time=12.694 ms
--- 110.0.0.6 ping statistics ---
5 packets transmitted, 5 packets received, 0.00% packet loss
How to connect the CISCO Nexus with Ansible over GNS3 simply?
I want to deploy and send command to Cisco Nexus OS with this ansible. In fact, I do not have real hardware switch and router, therefore I will use GNS3 simualator for this.
1. Environments.
To produce this environment. I need CISCO Nexus and Ansible over GNS3. If I want to apply in real world, I will follow this instruction, which explan how to install ansible control node. In GNS3 marketplace, there is appliance which offer the feature for ansible. I will use this.
With this GNS3 appliance, I will produce this topology like below.
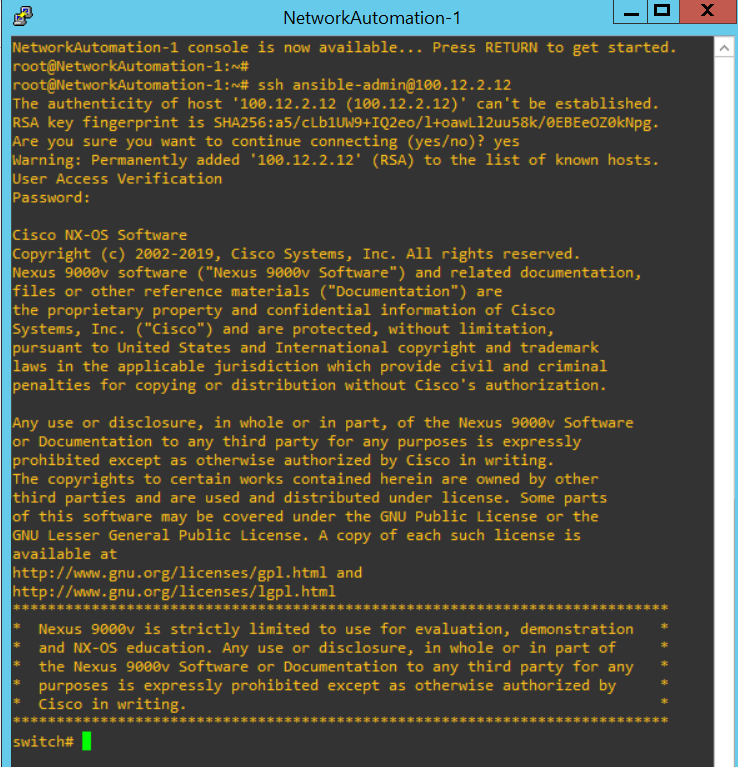
After configuration with above topology, I can login every switch/router with SSH like below.
In Network Automation host of GNS3, Ansible is pre-installed. I can verify the version like below. In my case, 2.7.11 is installed.
Now, I am ready to use ansible to deploy CISCO Nexus OS over GNS3.
When I met these concepts as the network engineer, it is not simple to understand. In my opinions, "Control Node" is the machine to create command and transfer to the switch/router. "Managed Nodes" are the switch/router. Inventory is the list of switch/router to access, which has IP address and username. "Task" is the action which like "show verson" command. "Playbooks" is the group of the "Task". In ansible, there are 2 option to run, ansible and ansible-playbook. I will show detail later in this post.
3. Variable Syntax for Ini-stype and Yml formation.
In this middle of thisinstruction, there are syntax example. During create inventory or playbook, I will meet 2 types of files, ini-style and yml format. They have different format to define variable. In ini-sytpe, key=value is correct. In yml format, key:value is correct.
4. Create the Inventory file.
"Working with Inventory" and "Build Your Inventory" are instruction how to create Inventory file. This inventory file is the list of switch which can be access with IP address and username. In this inventory file, I can list per host and make group with hosts.
From here, I can verify "/etc/ansible" directory is used default. In this directory, there are 2 files and 1 directory. "ansible.cfg" is the global configuration file. "hosts" is the inventory file.
In this post, I will try to access CISCO Nexus for the network automation. To create Inventory file, I should know how to define the connection method to switch/router. In this instruction, some parameters are explained. At first, I need to how to method to connection. In my case, I will select "network_cli" which is made by "CLI over SSH".
Second, I need what kinds of OS type will be existed. In my case, I have to try to access CISCO Nexus, there It should be nxos.
If I use the "Catalyst", I may use "enable" command.
With these factors, I can create Inventory file like below. I want to make "gns3_datacenter" which has zone_core, zone_1 and zone 2 elements.
":children" option is used to include element into the group. ":vars" option is used to define varaible such as ansibile host and ansible_connection. In this instruction, there are the behavioral inventory parameters
5. Create Password valut.
So far, I defined the host to access. However, the password part has still left. In ansible, there is the way to protect sensitive variable with ansible-vault such as password.
For this, I need to config file. In this "/etc/ansible/ansible.cfg", vault_password_file is commented. I need to change this part with what I want. In my case, "/etc/ansible/vault_password_file" is used.
After then, I will create vault_password_file with command below.
I will meet this error. I have searched through google so many times. However, I can not find out why this is happen. However, I have to comment "vault_password_file" again in "/etc/ansible/ansible.cfg".
After comment, I can run command above. I will get result like below. Memorize this value. Please note un-comment "vault_password_file".
6. Organizing host and group variables
I create ansible password with vault. Now I need to add this parameter into the configuration. At this time, I will use "Organizing host and group variables" method. Because the password could be different each Hardware devices. In ansible, "group_vars/" and "host_vars/" will be used to define. Please read this instruction.
Now I will create "group_vars" directory and create file with "group name" in Inventory file. In my case, I will use "gns3_datacenter"
Now I will add the "ansible_password" above into "/etc/ansible/group_vars/gns3_datacenter"
"hosts" parameter mean that group or host name in Inventory file. In the "tasks", I need to add module. In my case, I will use network module. This instruction will be helpful. In this example, I use "nxos_command" module. The below example come from "nxos_command".
the host group(s) to which the command should apply (in this case, all) the inventory (-i, the device or devices to target - without the trailing comma -i points to an inventory file) the connection method (-c, the method for connecting and executing ansible) the user (-u, the username for the SSH connection) the SSH connection method (-k, please prompt for the password) the module (-m, the ansible module to run) an extra variable ( -e, in this case, setting the network OS value)
In my case, I will select second method. I can run the ansible-playbook like below.
9. Debug and Display Result.
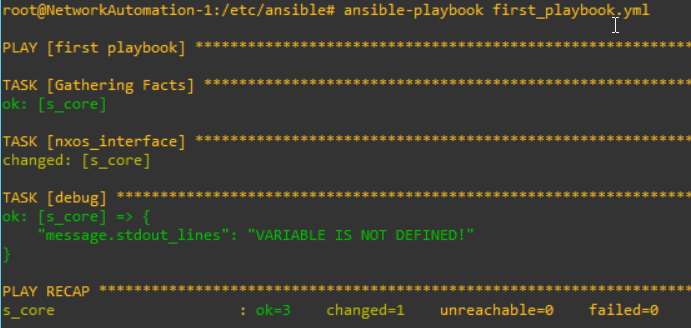
I check everything is good. However, I can not view the result by the monitor. For this, I will use "debug" and "register" concept. Now, I will revise the playbook like below.
# cat first_playbook.yml
- name: first playbook
hosts: gns3_datacenter
tasks:
- name: show version
nxos_command:
commands: show version
register: message
- debug: var=message.stdout_lines
With red contents, I will get the result like below.
10. Troubleshooting
If I meet this error, I need to check the username and password.
To print out the result, I can meet "variable is not defined" message.
I will replace the "register" and "debug" part like below
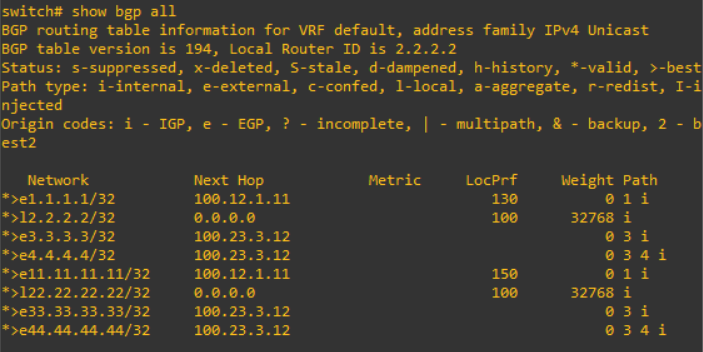
This instruction is good reference. In fact, I will analysis this instruction. BGP community is used for filtering and tagging information over routing information. Therefore, routing table information will be controlled by these condistions. Thus I can select the routing information to advertise or update in the table.
1. Pre-requiste (Basic BGP configuration)
This is my environment for this post.
S1
S2
S3
S4
interface Ethernet1/1
no switchport
ip address 100.12.1.11/16
no shutdown
!
interface loopback0
ip address 1.1.1.1/32
!
interface loopback1
ip address 11.11.11.11/32
!
router bgp 1
router-id 1.1.1.1
log-neighbor-changes
address-family ipv4 unicast
network 1.1.1.1/32
network 11.11.11.11/32
neighbor 100.12.2.11
remote-as 2
update-source Ethernet1/1
address-family ipv4 unicast
interface Ethernet1/1
no switchport
ip address 100.12.2.11/16
no shutdown
interface Ethernet1/2
no switchport
ip address 100.23.2.12/16
no shutdown
!
interface loopback0
ip address 2.2.2.2/32
!
interface loopback1
ip address 22.22.22.22/32
!
router bgp 2
router-id 2.2.2.2
log-neighbor-changes
address-family ipv4 unicast
network 2.2.2.2/32
network 22.22.22.22/32
neighbor 100.12.1.11
remote-as 1
update-source Ethernet1/1
address-family ipv4 unicast
neighbor 100.23.3.12
remote-as 3
update-source Ethernet1/2
address-family ipv4 unicast
interface Ethernet1/2
no switchport
ip address 100.23.3.12/16
no shutdown
interface Ethernet1/3
no switchport
ip address 100.34.3.13/16
no shutdown
!
interface loopback0
ip address 3.3.3.3/32
!
interface loopback1
ip address 33.33.33.33/32
!
router bgp 3
router-id 3.3.3.3
log-neighbor-changes
address-family ipv4 unicast
network 3.3.3.3/32
network 33.33.33.33/32
neighbor 100.23.2.12
remote-as 2
update-source Ethernet1/2
address-family ipv4 unicast
neighbor 100.34.4.13
remote-as 4
update-source Ethernet1/3
address-family ipv4 unicast
interface Ethernet1/3
no switchport
ip address 100.34.4.13/16
no shutdown
!
interface loopback0
ip address 4.4.4.4/32
!
interface loopback1
ip address 44.44.44.44/32
!
router bgp 4
router-id 4.4.4.4
log-neighbor-changes
address-family ipv4 unicast
network 4.4.4.4/32
network 44.44.44.44/32
neighbor 100.34.3.13
remote-as 3
update-source Ethernet1/3
address-family ipv4 unicast
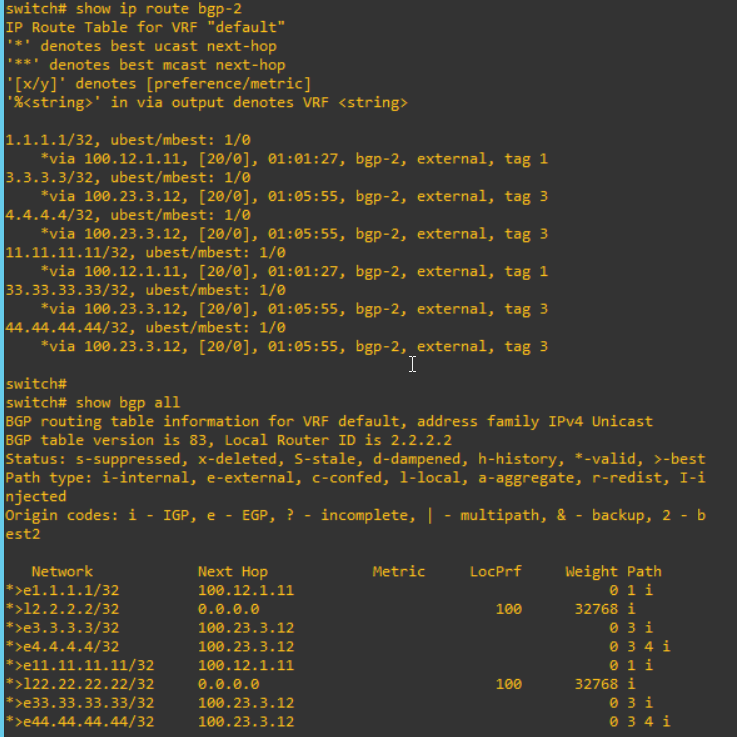
For nexus, "address-family ipv4 unicast" in neighbor parameter and "address-familiy ipv4 unicast" in global parameter are necessary to advertise to the peer. After configure these, I can verify the routing table and BGP information. From S2,
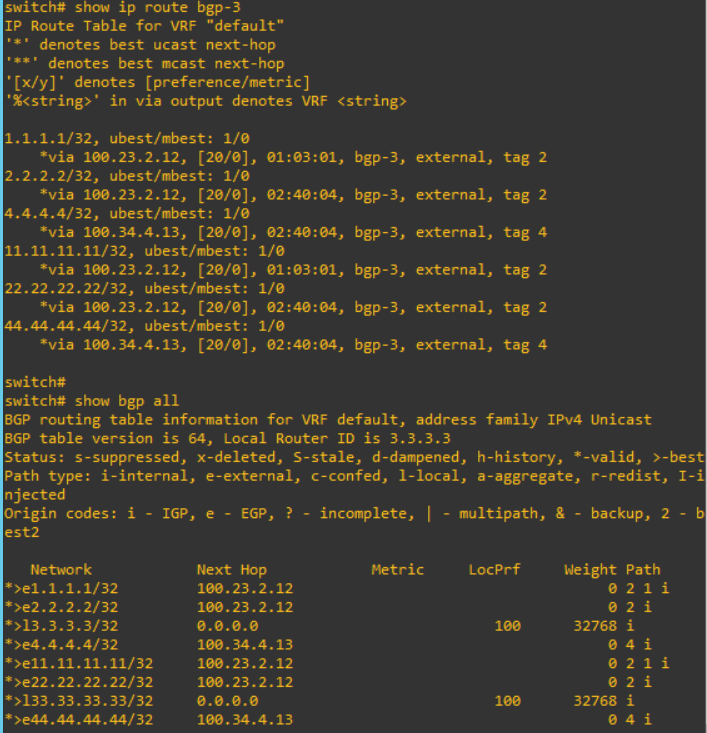
From S3,
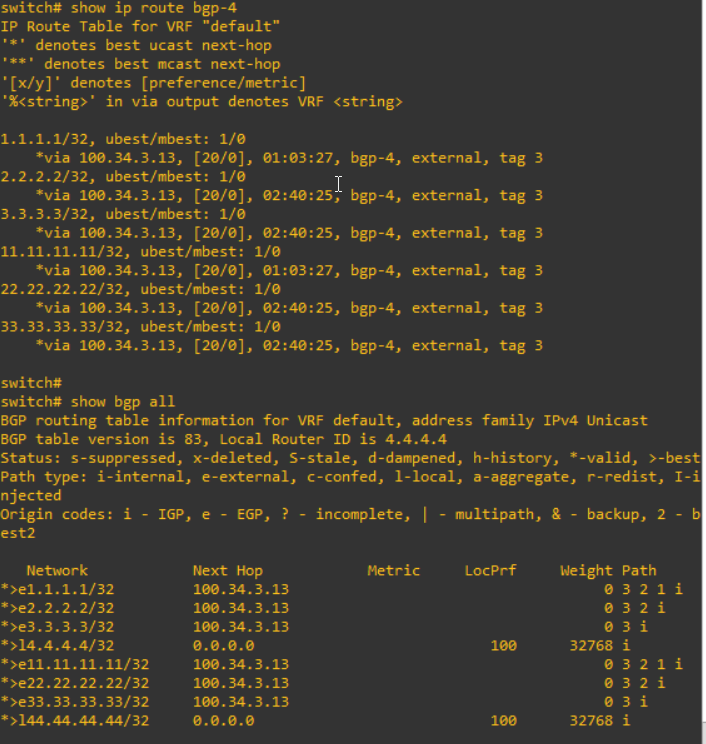
From S4,
I can confirm that the information from S1 such as "1.1.1.1" and "11.11.11.11" are advertised to S2, S3 and S4.
2. Configure send community
To use the BGP community, I have to configure "send community". There are 2 types, standard and extended. In this struction, the extended community has more information such as VPN services.
I will added the configuration like below.
S1
S2
S3
S4
router bgp 1
neighbor 100.12.2.11
address-family ipv4 unicast
send-community both
router bgp 2
neighbor 100.12.1.11
address-family ipv4 unicast
send-community both
neighbor 100.23.3.12
address-family ipv4 unicast
send-community both
router bgp 3
neighbor 100.23.2.12
address-family ipv4 unicast
send-community both
neighbor 100.34.4.13
address-family ipv4 unicast
send-community both
router bgp 4
neighbor 100.34.3.13
address-family ipv4 unicast
send-community both
Please note that there are any differences of routing table after these configuration above.
3. Configure Route-map in and out
To use the BGP community, the route-map is necessary. This route-map affect the routing table. In S3, I will add "route-map" configuration.
!
router bgp 1
neighbor 100.12.2.11
address-family ipv4 unicast
route-map to-remote-as2 out
end
!
"route-map to-remote-as2 out" mean that routing information to transfer out will be controlled with this route-map. Therefore, after this configuration, the routing table will be changed. "1.1.1.1" and "11.11.11.11" are removed.
Now, I will add the policy to set community.
ip prefix-list ip-prefix-1 seq 10 permit 1.1.1.1/32 ip prefix-list ip-prefix-2 seq 10 permit 11.11.11.11/32 route-map to-remote-as2 permit 10 match ip address prefix-list ip-prefix-1 set community 12:130 route-map to-remote-as2 permit 20 match ip address prefix-list ip-prefix-2 set community 12:150
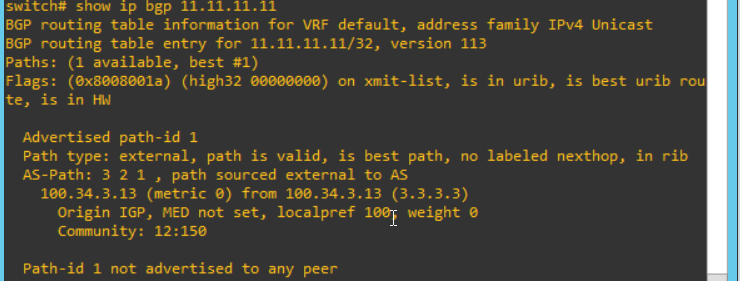
I check the routing table from S4. "1.1.1.1" and "11.11.11.11" will be updated.
And I can see more detail. I can see the community values are changed on each.
So far, I learn how to set the community with BGP. From now, I will handle how to get the community and use this. This is so similar with above. I will add configure into the S2.
!
router bgp 2
neighbor 100.12.1.11
address-family ipv4 unicast
route-map from-remote-as1 in
end
!
After configure this, the routing table will be changed. "1.1.1.1" and "11.11.11.11" are removed again.
Now, I will add some configuration to get community and use it in S2.
ip community-list expanded community-1 seq 1 permit "12:130"
ip community-list expanded community-2 seq 1 permit "12:150"
route-map from-remote-as1 permit 10
match community community-1
set local-preference 130
route-map from-remote-as1 permit 20
match community community-2
set local-preference 150
These configuration effect S2 routing table like below.
However, it does not effect S3 and S4, even if the community value is left.
How to outbound external connection of GN3 devices over remote server?
I use GNS3 simulator to study network feature sometimes. There is many instruction over internet. In this post, I will introduce how to use NAT fuction to connect to interet for outbound traffic.
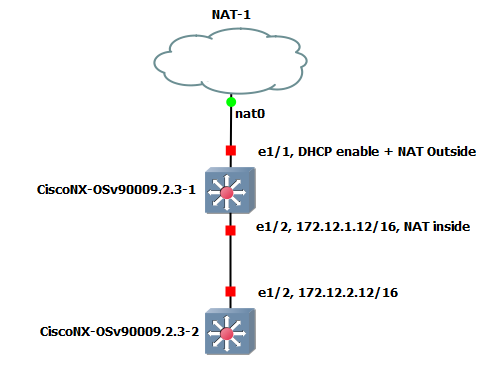
This is the my environment to re-produce in this post.
2. About NAT appliance (DHCP feature).
In GNS3, there is NAT appliance. It has the role to connect the physical interface on remote server virtually. This NAT appliance offers DHCP feature to assign IP address. This IP address determined the next hop against the Cisco switch/router. Thus, the Cisco switch/router should have DHCP feature.
feature dhcp
ip route 0.0.0.0/0 192.168.122.1
no ip dhcp relay
no ipv6 dhcp relay
interface Ethernet1/1
no switchport
ip address dhcp
no shutdown
After this configuration, I can verify the interface status with "show ip int br" command
And "ip route 0.0.0.0/0 192.168.122.1" is written. In the Linux host (remote server), I can see the interfaces like below.
With this interfaces, the packet will transfer to external side. I can see the masqurade rule in "iptables table" like below.
Now, I can send traffic to outside on switch 1. Please noteh that it is not possible on switch 2.
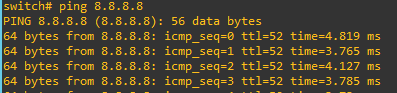
switch 1(config)#ip domain-lookup
switch 1(config)# ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8): 56 data bytes 64 bytes from 8.8.8.8: icmp_seq=0 ttl=53 time=19.257 ms 64 bytes from 8.8.8.8: icmp_seq=1 ttl=53 time=2.484 ms
3. Configuration NAT Inside and Outside
Switch 1 can send the packet to outside, however switch 2 can not. Because "192.168.122.0/24" network can only be masquraded in the remote server. This is the reason why the switch 1 has NAT feature. In this instruction, there is the explation for Cisco NAT concept.
Inside source translation is for inside --> outside traffic. Outside source translation is for outside --> inside traffic. At first, I will make the direction on Cisco switch 1.
feature nat
interface Ethernet1/1 no switchport ip address dhcp ip nat outside no shutdown
interface Ethernet1/2 no switchport ip address 172.12.1.12/16 ip nat inside no shutdown
4. Create Rule (NAT Policy) for outbound traffic.
In this post, I handle only outbound traffic. The main factor is that IP address for all traffic to outside should be changed with Switch 1 interface ethernet 1/1 IP address. In this post, It will be useful. I want all traffic to be sent.
ip access-list 1 10 permit ip any any
ip nat inside source list 1 interface Ethernet1/1 overload
5. Configure inside network (Switch 2).
So far, I made NAT firewall. From this part, it can assume internet network. However, I only use single switch/router simply.
ip route 0.0.0.0/0 172.12.1.12
interface Ethernet1/2
no switchport
ip address 172.12.2.12/16
no shutdown
This is normal configuration. There is nothing special. After default configuration. I can verify the outbound connection like below over switch 2.