Recently, I have some chance to study about the FRRouting. At that time, I do not have any Linux server. Thus, I decide that I use AWS Spot instance. After installation, I set up the OSPFv2 environment with simple configuration. However I can not estabilish the OSPF neighbor.
1. Simple OSPFv2 Configuration of FRRouting
I have 2 hosts which is direct connected each other. In fact, these hosts are located in the same subnet of the VPC.
| Host #1 | Host #2 |
| ip-10-11-0-200# show running-config Building configuration... Current configuration: ! frr version 7.3 frr defaults traditional hostname ip-10-11-0-200 log syslog informational no ipv6 forwarding service integrated-vtysh-config ! interface ens5 ip address 10.11.0.200/24 ip ospf hello-interval 1 ! interface lo ip address 1.1.1.1/32 ! router ospf ospf router-id 1.1.1.1 network 10.11.0.0/24 area 0.0.0.0 ! line vty ! end |
ip-10-11-0-229# show running-config Building configuration... Current configuration: ! frr version 7.3 frr defaults traditional hostname ip-10-11-0-229 log syslog informational no ipv6 forwarding service integrated-vtysh-config ! interface ens5 ip address 10.11.0.229/24 ip ospf hello-interval 1 ! interface lo ip address 1.1.1.2/32 ! router ospf ospf router-id 1.1.1.2 network 10.11.0.0/24 area 0.0.0.0 ! line vty ! end |
In FRRouting, I need one of configurations, "network <ip address> area <area-id>" and "ip ospf area <area-id>". In my case, I used "network <ip address> area <area-id>".
2. Multicast for OSPFv2
Have you ever heard about the multicast packet for OSPFv2? It is necessary factor to establish the connection.
| [ Correct Multicast Relationship] 15:35:33.303082 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 15:35:34.275218 IP 10.11.0.229 > 224.0.0.5: OSPFv2, Hello, length 48 |
On the same broadcast domain, I can see the both packets from the sender. However, I can not see all of things over AWS VPC network. It look like below
| 15:40:05.381662 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 15:40:06.381928 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 |
AWS does not support multicast default.
2. Enable the multicast feature for AWS VPC
Recently, AWS improve their feature of VPC with transit gateway. In this instruction, AWS show how to enable the multicast, even if there is limitation.

It is only 1 multicast source is possible. Because of this, I can not make success to establish OSPFv2 default. I need to request increase the quota.
2-1. Create transit gateway with Multicast
The below is the result of creation. There is "Multicast support" option. (Please note that this feature is not opened on all of the regions, In my case, I use Virginia region.)

2-2. Attach the VPC to Transit Gateway.
I need to attach the transit gateway with mulitcast domain to the VPC.
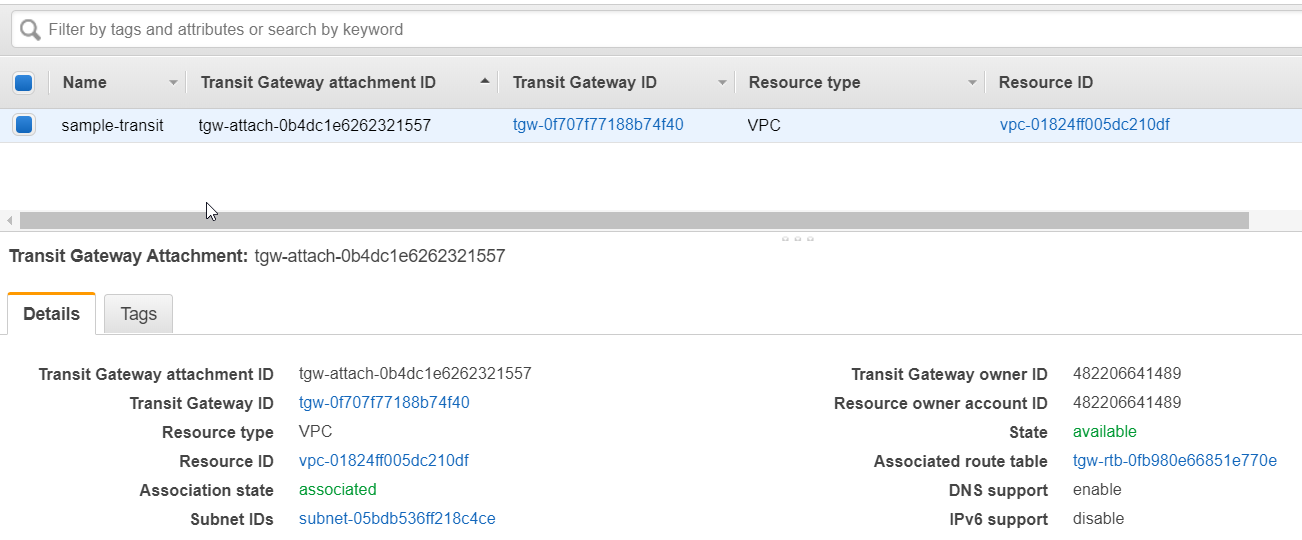
2-3. Associate the subnet in VPC to the transit Gateway.
I have to assign the subnet which make multicast work to multicast domain. This multicast domain is created by transit gateway.

2-4. Register the source and member for multicast.
The definition of the source and memeber is below.


For the OSPFv2, each host should be source and member. Thus I need 2 source and 2 member. However, I can not make 2 source at this time by limitation of AWS

"224.0.0.5" is the Multicast Group Address for OSPFv2.
3. The result after enabling Multicast
Even if the multicast does not activate fully. I can verify the multicast effect. Host #1 is source and member. Host #2 is only member. Thus Host #2 can not transfer the mulitcast over VPC network.
| [Host #1 Packets] 16:03:01.614874 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 16:03:02.615055 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 16:03:03.615173 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 16:03:04.615295 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 16:03:05.615409 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 16:03:06.615963 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 16:03:07.615972 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 root@ip-10-11-0-200:~# vtysh Hello, this is FRRouting (version 7.3). Copyright 1996-2005 Kunihiro Ishiguro, et al. ip-10-11-0-200# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface RXmtL RqstL DBsmL |
| [Host #2 Packets] 15:59:34.565227 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 15:59:34.566696 IP 10.11.0.229 > 224.0.0.5: OSPFv2, Hello, length 48 15:59:35.565246 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 15:59:35.566705 IP 10.11.0.229 > 224.0.0.5: OSPFv2, Hello, length 48 15:59:36.565372 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 15:59:36.566724 IP 10.11.0.229 > 224.0.0.5: OSPFv2, Hello, length 48 15:59:37.565376 IP 10.11.0.200 > 224.0.0.5: OSPFv2, Hello, length 44 root@ip-10-11-0-229:~# vtysh Hello, this is FRRouting (version 7.3). Copyright 1996-2005 Kunihiro Ishiguro, et al. ip-10-11-0-229# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface RXmtL RqstL DBsmL 1.1.1.1 1 Init/DROther 39.950s 10.11.0.200 ens5:10.11.0.229 0 0 0 |
This is the what I learned from the Test.
Reference
[ 1 ] https://docs.aws.amazon.com/vpc/latest/tgw/working-with-multicast.html
[ 2 ] https://docs.aws.amazon.com/vpc/latest/tgw/transit-gateway-quotas.html
[ 3 ] https://docs.aws.amazon.com/vpc/latest/tgw/tgw-multicast-overview.html
'Cloud Study > AWS' 카테고리의 다른 글
| How to use AWS AppStream 2.0? (1) | 2019.01.03 |
|---|---|
| How to use AWS workspace? (0) | 2019.01.02 |
| AWS Region ICMP Latency time estimation. (0) | 2018.11.22 |
| How to Install AWS JAVA SDK in Ubuntu 16.04, Linux (1) | 2018.09.13 |
| How to Upload Object into S3 with multipart-upload using S3API CLI (0) | 2018.09.11 |















































































 AWS_Region_ICMP.xlsx
AWS_Region_ICMP.xlsx







 tidcne-s2s-connection-1.txt
tidcne-s2s-connection-1.txt








